Writing Python inside your Rust code — Part 3
Contents
Have you ever seen the Rust compiler give a Python error?
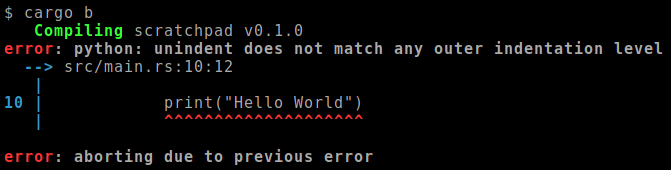
Or better, have you ever seen rust-analyzer complain about Python syntax?
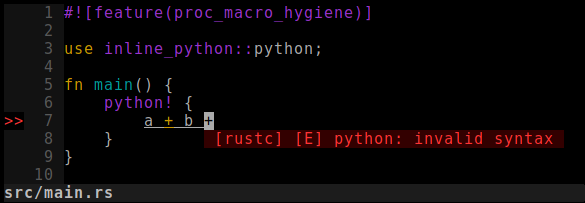
In this post, we’ll extend our python!{} macro to make that happen.
Previously: Part 2
Next: Part 4
Credit and special thanks: Everything described in this part was originally implemented for the inline-python crate by Maarten de Vries.
Compiling Python code
Before the Python interpreter executes your Python code,
it first compiles it to Python bytecode.
The bytecode for imported modules is usually cached in a directory called __pycache__, as .pyc files,
to save time the when the same code is imported next time.
Since the bytecode will only change when the source is changed,
it’d be interesting to see if we can make python!{} produce the bytecode at compile time,
since the Python code will not change after that anyway.
Then, the resulting program will not have to spend any time compiling the Python code
before it can execute it.
But first, what does “compiling” exactly mean for Python, as an interpreted language?
The Python Standard Library contains a module called dis,
which can show us the Python bytecode for a piece of code in a readable (disassembled) format:
$ python
>>> import dis
>>> dis.dis("abc = xyz + f()")
1 0 LOAD_NAME 0 (xyz)
2 LOAD_NAME 1 (f)
4 CALL_FUNCTION 0
6 BINARY_ADD
8 STORE_NAME 2 (abc)
10 LOAD_CONST 0 (None)
12 RETURN_VALUE
The Python statement abc = xyz + f() results in 7 bytecode instructions.
It loads some things by name (xyz, f, abc),
executes a function call, adds two things, stores a thing, and finally loads None and returns that.
We’ll not go into the details of this bytecode language,
but now we have a slightly clearer idea of what ‘compiling Python’ means.
Unlike many compiled languages, Python doesn’t resolve names during the compilation step.
It didn’t even notice that xyz (or f) is not defined,
but simply generated the instruction to load “whatever is named xyz” at run time.
Because Python is a very dynamic language,
you can’t possibly find out if a name exists without actually running the code.
This means that compiling Python mostly consists of parsing Python, since there’s not a lot of other things that can be done without executing it.
This is why trying to run a Python file with a syntax error in the last line will error out before even running the first line. The entire file gets compiled first, before it gets to executing it:
$ cat > bla.py
print('Hello')
abc() +
$ python bla.py
File "bla.py", line 2
abc() +
^
SyntaxError: invalid syntax
On the other hand, calling a non-existing function will only give an error once that line is actually executed. It passes through the compilation step just fine:
$ cat > bla.py
print('Hello')
abc()
$ python bla.py
Hello
Traceback (most recent call last):
File "bla.py", line 2, in <module>
abc()
NameError: name 'abc' is not defined
(Note the Hello in the output before the error.)
From Rust
Now how does one go about compiling Python to bytecode from Rust?
So far, we’ve used to PyO3 crate for all our Python needs,
as it provides a nice Rust interface for all we needed.
Unfortunately, it doesn’t have any functionality exposed related to Python bytecode.
However, it does expose the C interface of (C)Python,
through the pyo3::ffi module.
Normally, we wouldn’t use this C interface directly, but use all of PyO3’s nice wrappers that provide proper types and safety. But if the functionality we need is not wrapped by PyO3, we’ll have to call some of the C functions directly.
If we look through that C interface, we see a few functions starting with Py_Compile.
Looks like that’s what we need!
Py_CompileString
takes the source code string, a filename, and some parameter called start.
It returns a Python object representing the compiled code.
The filename makes it seem like it reads from a file, but the documentation tells us otherwise:
The filename specified by
filenameis used to construct the code object and may appear in tracebacks orSyntaxErrorexception messages.
So we can put whatever we want there, it is only used in messages as if the source code we provide was originally read from that file.
The start parameter is also not directly obvious:
The start token is given by start; this can be used to constrain the code which can be compiled and should be
Py_eval_input,Py_file_input, orPy_single_input.
It tells the function what the code should be parsed as: as an argument to
eval(),
as a .py file, or as a line of interactive input.
Py_eval_input only accepts expressions, and Py_single_input only a single statement.
So in our case, Py_file_input is what we want.
Let’s try to use it.
For now, we’ll just modify our existing run_python function to see how it works.
Once we have it working, we’ll try to move this to the procedural macro, to make it happen at compile time.
use pyo3::types::PyDict;
use pyo3::{AsPyRef, ObjectProtocol, PyObject};
use std::ffi::CString;
pub fn run_python(code: &str, _: impl FnOnce(&PyDict)) {
// Lock Python's global interpreter lock.
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let obj = unsafe {
// Call the Py_CompileString C function directly,
// using 0-terminated C strings.
let ptr = pyo3::ffi::Py_CompileString(
CString::new(code).unwrap().as_ptr(),
CString::new("dummy-file-name").unwrap().as_ptr(),
pyo3::ffi::Py_file_input,
);
// Wrap the raw pointer in PyO3's PyObject,
// or get the error (a PyErr) if it was null.
PyObject::from_owned_ptr_or_err(py, ptr)
};
// Print and panic if there was an error.
let obj = obj.unwrap_or_else(|e| {
e.print(py);
panic!("Error while compiling Python code.");
});
// Just print the result using Python's `str()` for now.
println!("{}", obj.as_ref(py).str().unwrap());
todo!();
}
#![feature(proc_macro_hygiene)]
use inline_python::python;
fn main() {
python! {
print("hi")
}
}
$ cargo r
Compiling inline-python v0.1.0
Compiling example v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/example`
<code object <module> at 0x7f04ba0f65b0, file "dummy-file-name", line 6>
thread 'main' panicked (...)
So we got a ‘code object’. Sounds good.
Now, how to execute it?
Digging a bit through the Python C API docs will lead to
PyEval_EvalCode:
PyObject* PyEval_EvalCode(PyObject *co, PyObject *globals, PyObject *locals);
This looks very much like PyO3’s Python::run function that we used earlier,
except it takes the code as a PyObject instead of a string.
use pyo3::types::PyDict;
use pyo3::{AsPyPointer, PyObject};
use std::ffi::CString;
pub fn run_python(code: &str, f: impl FnOnce(&PyDict)) {
// <snip>
// Make the globals dictionary, just like in Part 2.
let globals = PyDict::new(py);
f(globals);
// Execute the code object.
let result = unsafe {
let ptr = pyo3::ffi::PyEval_EvalCode(
obj.as_ptr(),
globals.as_ptr(),
std::ptr::null_mut(),
);
PyObject::from_owned_ptr_or_err(py, ptr)
};
if let Err(e) = result {
e.print(py);
panic!("Error while executing Python code.");
}
}
$ cargo r
Compiling inline-python v0.1.0
Compiling example v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/example`
Traceback (most recent call last):
File "dummy-file-name", line 6, in <module>
NameError: name 'print' is not defined
thread 'main' panicked (...)
Uh, what? 'print' is not defined?
It executed the Python code, but somehow Python forgot about its own print() function?
Looks like the builtins aren’t loaded. Is that something PyO3 did for us before?
When we take a look at the source code of PyO3,
we see that it loads the __main__ module.
But if we take a closer look, we see the import is completely ignored in case we provide our own globals dictionary, like we did.
All that’s left is a call to PyRun_StringFlags.
Into CPython’s source code we go.
There
we see PyRun_StringFlags calls an internal function called run_mod.
Going deeper,
run_mod calls run_eval_code_obj, and … gotcha!
/* Set globals['__builtins__'] if it doesn't exist */
if (globals != NULL && PyDict_GetItemString(globals, "__builtins__") == NULL) {
if (PyDict_SetItemString(globals, "__builtins__",
tstate->interp->builtins) < 0) {
return NULL;
}
}
v = PyEval_EvalCode((PyObject*)co, globals, locals);
It sneakily adds __builtins__ to the globals dictionary, before calling PyEval_EvalCode.
This wasn’t documented in the API reference, but at least the project is open source so we could find out ourselves.
Going back a bit, what was up with that __main__ module that PyO3 uses as a fallback?
What does it even contain?
$ python
>>> import __main__
>>> dir(__main__)
['__annotations__', '__builtins__', '__doc__', '__loader__', '__main__', '__name__', '__package__', '__spec__']
Oh! __builtins__! And some other things that look like they should be there by default as well.
Maybe we should just import __main__:
// <snip>
// Use (a copy of) __main__'s dict to start with, instead of an empty dict.
let globals = py.import("__main__").unwrap().dict().copy().unwrap();
f(globals);
// <snip>
$ cargo r
Compiling inline-python v0.1.0 (/home/mara/blog/scratchpad/inline-python)
Compiling example v0.1.0 (/home/mara/blog/scratchpad)
Finished dev [unoptimized + debuginfo] target(s) in 0.44s
Running `target/debug/example`
hi
Yes!
At compile time
Okay, now that compiling and running as separate steps works, the next challenge is to try to move the first step to the procedural macro, so it happens at compile time.
First of all, this means we’ll be using Python in our proc-macro crate. So we add PyO3 to its dependencies:
[dependencies]
# <snip>
pyo3 = "0.9.2"
We then split our run_python function into two parts.
The first part, that compiles the code, goes into our proc-macro crate:
fn compile_python(code: &str, filename: &str) -> PyObject {
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let obj = unsafe {
let ptr = pyo3::ffi::Py_CompileString(
CString::new(code).unwrap().as_ptr(),
CString::new(filename).unwrap().as_ptr(),
pyo3::ffi::Py_file_input,
);
PyObject::from_owned_ptr_or_err(py, ptr)
};
obj.unwrap_or_else(|e| {
e.print(py);
panic!("Error while compiling Python code.");
})
}
And the second half stays where it is:
pub fn run_python(code: PyObject, f: impl FnOnce(&PyDict)) {
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let globals = py.import("__main__").unwrap().dict().copy().unwrap();
f(globals);
let result = unsafe {
let ptr = pyo3::ffi::PyEval_EvalCode(
code.as_ptr(),
globals.as_ptr(),
std::ptr::null_mut()
);
PyObject::from_owned_ptr_or_err(py, ptr)
};
if let Err(e) = result {
e.print(py);
panic!("Error while executing Python code.");
}
}
All that’s left, is passing the PyObject from the first function into the second one.
But, uh, wait. They run in different processes.
The first function runs as part of rustc while buiding the program, and the second runs much later, while executing it.
The PyObject from compile_python is simply a pointer, pointing to somewhere in the memory of the first process,
which is long gone by the time we need it.
Before, we only had a string to pass on. So then we just used quote!() to
turn that string into a string literal token (e.g. "blabla")
which ended up verbatim in the generated code.
But now, we have an object that represents compiled Python code, presumably containing Python bytecode, as we’ve seen above.
If we can actually extract the bytecode, we can put that in the generated code as a byte-string (b"\x01\x02\x03") or array ([1,2,3]),
so it can be properly embedded into the resulting executable.
Browsing a bit more through Python C API, the ‘data marshalling’ module looks interesting. According to Wikipedia:
In computer science, marshalling or marshaling is the process of transforming the memory representation of an object to a data format suitable for storage or transmission
Sounds good!
PyMarshal_WriteObjectToString and
PyMarshal_ReadObjectFromString
are exactly what we need.
Let’s start with the proc-macro side.
PyObject* PyMarshal_WriteObjectToString(PyObject *value, int version);
It wants a PyObject to turn into bytes, the encoding format version, and returns a bytes object.
As for the version number, the documentation tells us: ‘Py_MARSHAL_VERSION indicates the current file format (currently 2).’
$ rg Py_MARSHAL_VERSION cpython/
cpython/Include/marshal.h
10:#define Py_MARSHAL_VERSION 4
...
Uh. Okay. Well, let’s just use that one. PyO3 wrapped it as pyo3::marshal::VERSION.
fn compile_python(code: &str, filename: &str) -> Literal {
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let obj = /* snip */;
let bytes = unsafe {
let ptr = pyo3::ffi::PyMarshal_WriteObjectToString(obj.as_ptr(), pyo3::marshal::VERSION);
PyBytes::from_owned_ptr_or_panic(py, ptr)
};
Literal::byte_string(bytes.as_bytes())
}
And in the proc_macro function itself:
// <snip>
// We take the file name from the 'call site span',
// which is the place where python!{} was invoked.
let filename = proc_macro::Span::call_site().source_file().path().display().to_string();
let bytecode = compile_python(&source, &filename);
quote!(
inline_python::run_python(
// Instead of #source, a string literal ("...") containing the raw source,
// we now provide a byte string literal (b"...") containing the bytecode.
#bytecode,
// <snip>
);
).into()
$ cargo b
Compiling inline-python-macros v0.1.0
Compiling inline-python v0.1.0
Compiling example v0.1.0
error[E0308]: mismatched types
--> src/main.rs:7:5
|
7 | / python! {
8 | | c = 100
9 | | print('a + 'b + c)
10 | | }
| |_____^ expected struct `pyo3::object::PyObject`, found `&[u8; 102]`
|
Perfect!
The code was compiled into a byte array (of 102 bytes, apparently)
and inserted into the generated code,
which then fails to compile because we still have to convert the bytes back into a PyObject.
On we go:
pub fn run_python(bytecode: &[u8], f: impl FnOnce(&PyDict)) {
let gil = pyo3::Python::acquire_gil();
let py = gil.python();
let code = unsafe {
let ptr = pyo3::ffi::PyMarshal_ReadObjectFromString(
bytecode.as_ptr() as *const _,
bytecode.len() as isize
);
PyObject::from_owned_ptr_or_panic(py, ptr)
};
// <snip>
$ cargo r
Compiling inline-python v0.1.0
Compiling example v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.37s
Running `target/debug/example`
hi
🎉
Errors
Now that we’re compiling the Python code during compile time,
syntax errors should show up during cargo build, before even running the code.
Let’s see what that looks like now:
#![feature(proc_macro_hygiene)]
use inline_python::python;
fn main() {
python! {
!@#$
}
}
$ cargo build
Compiling example v0.1.0
File "src/main.rs", line 6
!@#$
^
SyntaxError: invalid syntax
error: proc macro panicked
--> src/main.rs:5:5
|
5 | / python! {
6 | | !@#$
7 | | }
| |_____^
|
= help: message: Error while compiling Python code.
And there you go, the Rust compiler giving a Python error!
It’s a bit of a mess though.
Our macro first lets Python print the error (which contains the correct file name and line number!),
and then panics, causing the Rust compiler to show the panic message as an error about the whole python!{} block.
Ideally, the error would be displayed like any other Rust error. That way, it’ll be less noisy, and IDEs will hopefully be able to point to the right spot automatically.
Pretty errors
There are several ways to spit out errors from procedural macros.
The first one we’ve already seen: just panic!().
The panic message will show up as the error, and it will point at the entire macro invocation.
The second one is to not panic, but to generate code that will cause a compiler error afterwards.
The compile_error!() macro
will generate an error as soon as the compiler comes across it.
So, by emitting code containing a compile_error!("..."); statement,
a compiler error will be displayed.
But where will that error point at? Normally, when such a statement appears in Rust code,
it’ll point directly at the compile_error!() invocation itself.
But if a macro generates it, it doesn’t appear in the orignal code, so what then?
Well, that’s up to the macro itself. For every token it generates, it can also set its Span,
containing the location information. By lying a bit, we can make the error appear everywhere:
#[proc_macro]
pub fn python(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
// Get the span of the second token.
let second_token_span = TokenStream::from(input).into_iter().nth(1).unwrap().span();
// Generate code that pretends to be located at that span.
quote_spanned!(second_token_span =>
compile_error!("Hello");
).into()
}
python! {
one two three
}
$ cargo build
Compiling inline-python-macros v0.1.0
Compiling inline-python v0.1.0
Compiling example v0.1.0
error: Hello
--> src/main.rs:6:13
|
6 | one two three
| ^^^
The third and last method is more flexible, but (at the time of writing) unstable and gated behind #![feature(proc_macro_diagnostic)].
This feature adds functions like .error(),
.warning(),
and .note() on proc_macro::Span.
These functions return a Diagnostic
which we can .emit(), or first add more notes to:
#[proc_macro]
pub fn python(input: proc_macro::TokenStream) -> proc_macro::TokenStream {
let second_token_span = input.into_iter().nth(1).unwrap().span();
second_token_span.error("Hello").note("World").emit();
quote!().into()
}
Compiling inline-python-macros v0.1.0
Compiling inline-python v0.1.0
Compiling example v0.1.0
error: Hello
--> src/main.rs:6:13
|
6 | one two three
| ^^^
|
= note: World
Since we already use nightly features anyway, let’s just go for this one.
Displaying Python errors
The PyErr that we get from Py_CompileString represents a SyntaxError.
We can extract the SyntaxError object using .to_object(), and then access the properties lineno and msg to get the details:
fn compile_python(code: &str, filename: &str) -> Result<Literal, (usize, String)> {
// <snip>
let obj = obj.map_err(|e| {
let error = e.to_object(py);
let line: usize = error.getattr(py, "lineno").unwrap().extract(py).unwrap();
let msg: String = error.getattr(py, "msg").unwrap().extract(py).unwrap();
(line, msg)
})?;
// <snip>
Ok(...)
}
Then all we need to do, is find the Spans for that line, and emit the Diagnostic:
// <snip>
s.reconstruct_from(input.clone()); // Make a clone, so we keep the original input around.
// <snip>
let bytecode = compile_python(&source, &filename).unwrap_or_else(|(line, msg)| {
input
.into_iter()
.map(|x| x.span().unwrap()) // Get the spans for all the tokens.
.skip_while(|span| span.start().line < line) // Skip to the right line
.take_while(|span| span.start().line == line) // Take all the tokens on this line
.fold(None, |a, b| Some(a.map_or(b, |s: proc_macro::Span| s.join(b).unwrap()))) // Join the Spans into a single one
.unwrap()
.error(format!("python: {}", msg))
.emit();
Literal::byte_string(&[]) // Use an empty array for the bytecode, to allow rustc to continue compiling and find other errors.
});
// <snip>
python! {
print("Hello")
if True:
print("World")
}
$ cargo build
Compiling inline-python-macros v0.1.0
Compiling inline-python v0.1.0
Compiling example v0.1.0
error: python: expected an indented block
--> src/main.rs:8:9
|
8 | print("World")
| ^^^^^^^^^^^^^^
🎉
Success!
Replacing all the remaining .unwrap()s by nice errors is left as an exercise to the reader. :)
RLS / rust-analyzer
Now how to make it show up nicely in your IDE, when using a Rust language server like rust-analyzer?
Well.. Turns out that already works!
All you need to do is make sure executing procedural macros is enabled (e.g. "rust-analyzer.procMacro.enable": true),
and poof, magic.
✨
What’s next?
In the next post,
we’ll make it possible to keep the variables of a python!{} block around
after execution to get data back into Rust, or re-use them in another python!{} block:
let c: Context = python! {
abc = 5
};
assert_eq!(c.get::<i32>("abc"), 5);
c.run(python! {
assert abc == 5
});
In order to do so, we’ll extend the macro to make its behaviour depend on whether it’s used as an argument or not.