Writing Python inside your Rust code — Part 1A
Contents
Before continuing to extend our python!{} macro in part 2,
let’s explore some things in more detail first.
Previously: Part 1
Next: Part 2
Why?
First of all: “Why?” Why would anyone even want to embed Python in their Rust code? Is this just a fun experiment with no real purpose, or is it useful in ‘real world’ situations?
Originally, I just wanted to play with Rust macros and see whether this was possible at all. Quite a few of my programming adventures start with “this sounds impossible, let’s do it!”
However, as soon as it looked like it was actually going to work, the idea popped up of using Matplotlib (a Python library for visualising data) directly in Rust. I was working with some Rust code that would write data to a csv file, and then run a separate Python script to visualise it. That worked fine, but just not as convenient as directly calling Matplotlib’s functions on the (Rust) data would be.
And that works now, with the inline-python crate:
fn main() {
// Imagine some complicated Rust code producing this data.
let data = vec![(4, 3), (2, 8), (3, 1), (4, 0)];
python! {
import matplotlib.pyplot as plt
plt.plot('data)
plt.show()
}
}
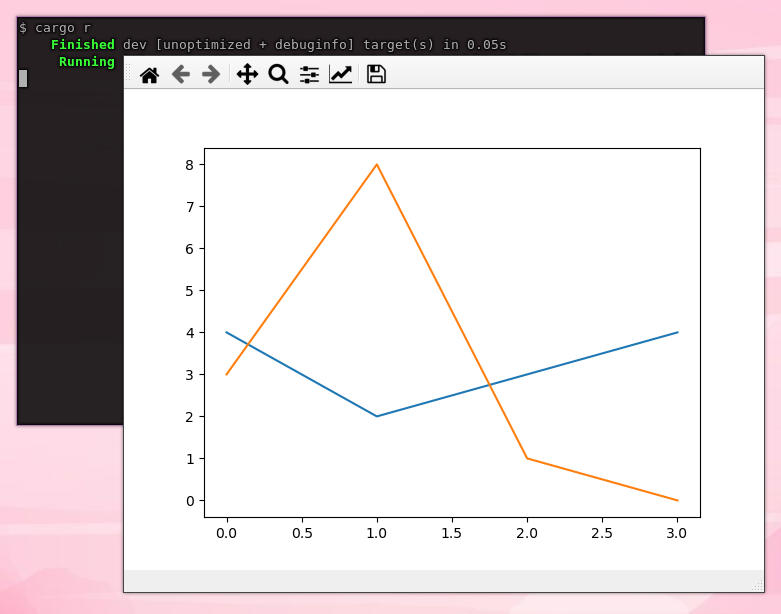
I’d have used a Rust visualisation library, but there’s no fully-featured replacement for Matplotlib at this time.
The downsides of mixing Python in your Rust code are basically the same as using Python ’the normal way’. Users will need to have Python and your dependencies installed, and things like performance and type safety leave some things to be desired. But it can be a great replacement for tools that already relied on Python anyway.
There are many Python libraries that are missing an equivalent in the Rust ecosystem. If the alternative is to run a separate Python script from Rust and parse its output, it might be a better idea to go for the easier and less fragile option of embedding the Python snippets, without having to think about how to pass your data around.
Syntax issues
Okay, back to the details!
What happens if someone wants to use single-quoted strings, which are valid in Python but not in Rust?
What about the // operator of Python,
which starts a comment in Rust?
Are there any other potential issues?
Single-quoted strings
Let’s try a single-quoted string:
fn main() {
python! {
print('hello')
}
}
$ cargo r
Compiling python-macro v0.1.0
Compiling scratchpad v0.1.0
error: character literal may only contain one codepoint
--> src/main.rs:6:15
|
6 | print('hello')
| ^^^^^^^
|
help: if you meant to write a `str` literal, use double quotes
|
6 | print("hello")
| ^^^^^^^
Yup, that’s not accepted by rustc.
Even though the things inside python!{} are not going to be parsed as Rust code,
it still gets tokenized as Rust code.
And 'hello' is simply not a valid Rust token,
since single quotes are used only for character literals in Rust (and lifetimes).
Let’s try 'x', which should be both a valid Rust token (as a character literal),
and a valid string in Python:
fn main() {
python! {
print('x')
}
}
$ cargo r
Compiling scratchpad v0.1.0
Finished dev [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/scratchpad`
x
Yup, that works.
The important observation to make here
is that even though the Rust tokeniser has given a meaning to 'x' (i.e. ’this is a character literal’),
the meaning of tokens to Rust is completely ignored by our macro,
which just passes the raw source to Python.
So, our python!{} macro can only ever accept Python code that can be tokenized (not parsed) as valid Rust code,
even though it doesn’t matter at all what it gets tokenized as.
We’ll just have to cut our losses, and accept that single quoted strings are just not going to work. Luckily this is not too big of a problem here, as Python also supports double-quoted strings just fine.
Let’s look for any other issues with string literals.
Escaped characters
According to the Python documentation,
Python supports quite a lot of escape sequences in string literals:
\ followed by a newline, \\, \', \", \a, \b, \f, \n, \r, \t, \v, octal escapes like \012, hexadecimal escapes like \x7F,
\N{..}, \U.. and \u...
If we compare that to the list of escape sequences allowed in Rust
(i.e. allowed by the Rust tokeniser),
we quickly see that it doesn’t match Python’s list.
The most common ones like \n and \" are there, but others like \a and \v don’t exist in Rust.
Again it’s important to realize that it doesn’t matter if the meaning of an escape sequence is the same in both languages. Rust will tokenize the code, but we completely ignore any meaning it gave to it.
For example, Rust doesn’t have octal escape sequences like \077.
However, Rust does have a \0 escape sequence.
The result is that strings like "\077" can still be used without problems in our python!{} macro.
Rust will parse that as a '\0' followed by two '7's,
and Python will still parse that as a single \077 like it always would.
So again, this is unfortunate, but not too big of a problem, as at least the most common escape codes are still accepted.
Triple quoted strings
To my surprise, triple quoted strings just seemed to work.
"""asdf""" is valid in Python, but doesn’t look like valid Rust to me.
If you take a close look however, we can see that we just got lucky here, and that it can be tokenized as Rust as three tokens:
- the empty string literal
"", - the string literal
"asdf", and - the empty string literal
"".
Again, we don’t care that Rust thinks of this as three separate strings.
After we stick these tokens back together and give it to Python, it’ll just see """asdf""" again.
The main reason to use triple quoted strings in Python, is because they can span over multiple lines. We’re in luck here: Rust’s regular string literals already allow that, so any newlines will just happily end up in the second of the three Rust tokens.
The only other difference triple quoted strings have over regular ones in Python,
is that they allow quotes to appear within (as long as it’s not three of them in a row): """a " b """
That will still break in python!{}, unfortunately.
Comments and the // operator
The biggest problem are comments, which start with // in Rust, and # in Python.
And to make it worse, // might appear in valid Python code, as the
floor divison operator.
#-comments can work, but with a few problems.
The Rust tokeniser just tokenizes a # just fine, but it won’t stop there.
It doesn’t see it as the start of a comment, so it’ll continue tokenizing the rest of the line.
That means that all your #-comments will need to be valid Rust tokens:
# This is okay.
# But 'this' is not.
That’s no good.
Because of this, it’d probably make sense to just use // comments in python!{} blocks instead of #-comments.
That way, it’s also consistent with comments in the surrounding Rust code, and
you don’t need to configure your editor to syntax-highlight #-comments.
And since the tokeniser already threw out our //-comments anyway,
we don’t even have to do anything to make this work.
fn main() {
python! {
print("hello") // Already works
}
}
The only problem left is the // operator.
The current version of inline-python let’s you write ## instead, which it replaces by //.
It’s not a pretty solution, but at least you can still use this operator.
Other tokens
I’ll not bore you to death by going over every other difference in tokens between the languages.
But if you were to look through every single type of Python token we haven’t discussed yet,
you’ll quickly notice we’re pretty lucky with all the other syntax.
Integers (with _ separators and prefixes like 0b, 0o, 0x),
floats, operators, etc. all tokenize just fine as Rust tokens.
Even the syntax for raw string literals (r"..") is the same in both languages
(although there is a tiny difference with how they handle \").
The full list of problems can be found in the inline-python documentation, and is luckily not much longer than what we’ve already discussed. They are important to keep in mind, but definitely not a show stopper.
Span::source_text
In part 1, we went through a lot of trouble
to reconstruct the original source code using the Span line and column
numbers.
An option that didn’t exist yet when I first wrote this code, but does exist now,
is to join
all the Span’s of the tokens,
and then call source_text() on the result.
Sounds easier!
Let’s try:
#[proc_macro]
pub fn python(input: TokenStream) -> TokenStream {
let mut tokens = input.into_iter();
let mut span = tokens.next().unwrap().span();
while let Some(token) = tokens.next() {
span = span.join(token.span()).unwrap();
}
let source = span.source_text().unwrap();
println!("-----");
println!("{}", source);
println!("-----");
quote!( run_python(#source); ).into()
}
fn main() {
python! {
print("hello")
print("world")
}
}
$ cargo r
Compiling python-macro v0.1.0
Compiling scratchpad v0.1.0
-----
print("hello")
print("world")
-----
Finished dev [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/scratchpad`
File "<string>", line 2
print("world")
^
IndentationError: unexpected indent
Hm, that didn’t go too well.
Fixing the white-space
Our source_text starts at the first token, so at the print, not right after the { of python! {, so
the first line appears to start at the first column, whereas the second line does have its indentation preserved.
Also note how the Python error refers to line 2, instead of line 7 (where this line appears in my .rs file),
because we no longer fill things up with newlines and spaces.
Let’s fix that. This time we only have to do it once at the start, instead of for every token:
let source =
"\n".repeat(span.start().line - 1) +
&" ".repeat(span.start().column) +
&span.source_text().unwrap();
$ cargo r
Compiling python-macro v0.1.0
Compiling scratchpad v0.1.0
-----
print("hello")
print("world")
-----
Finished dev [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/scratchpad`
File "<string>", line 6
print("hello")
^
IndentationError: unexpected indent
Okay, the indentation is back, and the line number is correct. But now we’re back to a problem we faced before: Python wanting code to start at a zero indentation level.
Let’s fix that, by stripping the initial indentation:
let n = span.start().column;
let original_source = source;
let mut source = String::new();
for line in original_source.lines() {
let (indent, line) = line.split_at(n.min(line.len()));
assert!(!indent.contains(|c| c != ' '), "Invalid indentation");
source += line;
source += "\n";
}
$ cargo r
Compiling python-macro v0.1.0
Compiling scratchpad v0.1.0
-----
print("hello")
print("world")
-----
Finished dev [unoptimized + debuginfo] target(s) in 0.50s
Running `target/debug/scratchpad`
hello
world
Okay, that works again.
Now the question is whether we’re better off than before. The code is definitely shorter, but still far from trivial. It also has quite a few subtle problems.
Problems
For example, code that is indented with tabs instead of spaces will now break. We could add more code to replace tabs by spaces, or detect tabs and count them differently for the column number. The approach from part 1 didn’t have to do anything special here. Since all white-space was reconstructed using spaces and newlines, tabs were already converted automatically.
Another problem with this approach would appear when we extend our python!{} macro,
when we want to do more than just execute the Python code verbatim.
We’re going to add a way to refer to Rust variables from within the Python code.
This will have some sort of syntax (e.g. $var or 'var) which will require some basic parsing of the Python code,
since we don’t want to interpret words inside a string literal as variables too, for example.
With the source_text approach, we’ll have to do this parsing ourselves.
Or we might be able to borrow a Python parser from some library.
However, there is already a simple parser that went over all the Python code and nicely marked all the tokens that could be identifiers for us:
the Rust tokeniser.
As we’ve seen earlier in this post, it’s not a great idea to tokenize Python using a Rust tokeniser, but we don’t really have a choice here. It already happened. So we might as well use its result, which is perfectly usable for this purpose.
Another important difference is that source_text preserves comments, unlike our previous approach.
Does this mean the // operator is usable again?
fn main() {
python! {
print(1 // 2)
print("world")
}
}
$ cargo r
Compiling scratchpad v0.1.0
error: mismatched closing delimiter: `}`
--> src/main.rs:8:5
|
5 | python! {
| - closing delimiter possibly meant for this
6 | print(1 // 2)
| - unclosed delimiter
7 | print("world")
8 | }
| ^ mismatched closing delimiter
Nope.
As you could already tell by the syntax highlighting in the snippet,
Rust still sees everything after the // as a comment (including the closing )),
causing a mismatched delimiters error.
Also, comments after our last token will not be visible to us, just like the white-space before the first token were gone.
So, if the last line of Python code is a = 10 // 2, a will silently be set to 10 instead of 5.
In conclusion, string_text is not a silver bullet.
It definitely makes some things easier,
but it doesn’t really solve most of our problems,
and even makes some things harder for later features.
Unfortunately, none of the approaches are anywhere near perfect. So let’s just continue with our first approach. :)
What’s next?
In part 2 we’ll make it possible to use Rust variables in the Python code.